Governance
The Common Domain Model is an open standard project hosted under FINOS, the Fintech Open Source Foundation, starting in February 2023.
The standard is developed through the Community Specification open governance process, and underlying code assets are released under the Community Specification License 1.0. For versions before 4.0.0 and other license details, check Notice.md.
For a more detailed overview of the existing Working Group and standard Participants, Editors and Maintainers, please see Governance.md. For more information on discussions and announcements subscribe to our mailing list using the following link.
A proposal can be defined at a conceptual level or a logical level (i.e. in code). In each case, the proposal must be developed in line with the CDM design-principles and agile-development-approach and submitted to FINOS staff and the Architecture & Review Committee for approval. In some instances, the proposal may not be immediately approved but may be assigned to an existing or new Working Group for the purpose of reviewing, revising or extending the proposal.
Once approved, the amendment will be scheduled to be merged with the CDM's main code branch by the CDM Maintainers.
Roles
The CSL specifies three different contribution roles for each specific Working Group:
- Maintainers - those who drive consensus within the working group
- Editors - those who codify ideas into a formal specification
- Participants - anyone who provides contributions to the project under a signed CSL CLA. A great way to sign the CLA is to open a Pull Request to add your name to the Participants.md file.
Working Groups
2.1.0 Any Participant may propose a Working Group. Proposals for the formation of a new Working Group are made by completion of a new new CDM Working Group template, clearly stating the objectives, deliverables and committed maintainers/editors for the proposed Working Group.
2.1.1 Approval of Specification Changes by Working Groups. Participants of each Working Group approve the “proposed” changes from that working group; the “approved changes” within a given Working Group will be brought to the Steering Working Group as a proposed “Pre-Draft” contribution.
- Participants of the CDM Steering Working Group approve DRAFT specification releases.
- Maintainers of the CDM Steering Working Group will approve merging of the proposed “Pre-Draft” changes (coming from other Working Groups or otherwise from community) into the repo.
2.2.0 CDM Steering Working Group. The CDM Steering Working Group will review and approve completed Working Group formation proposals per 2.1.0.
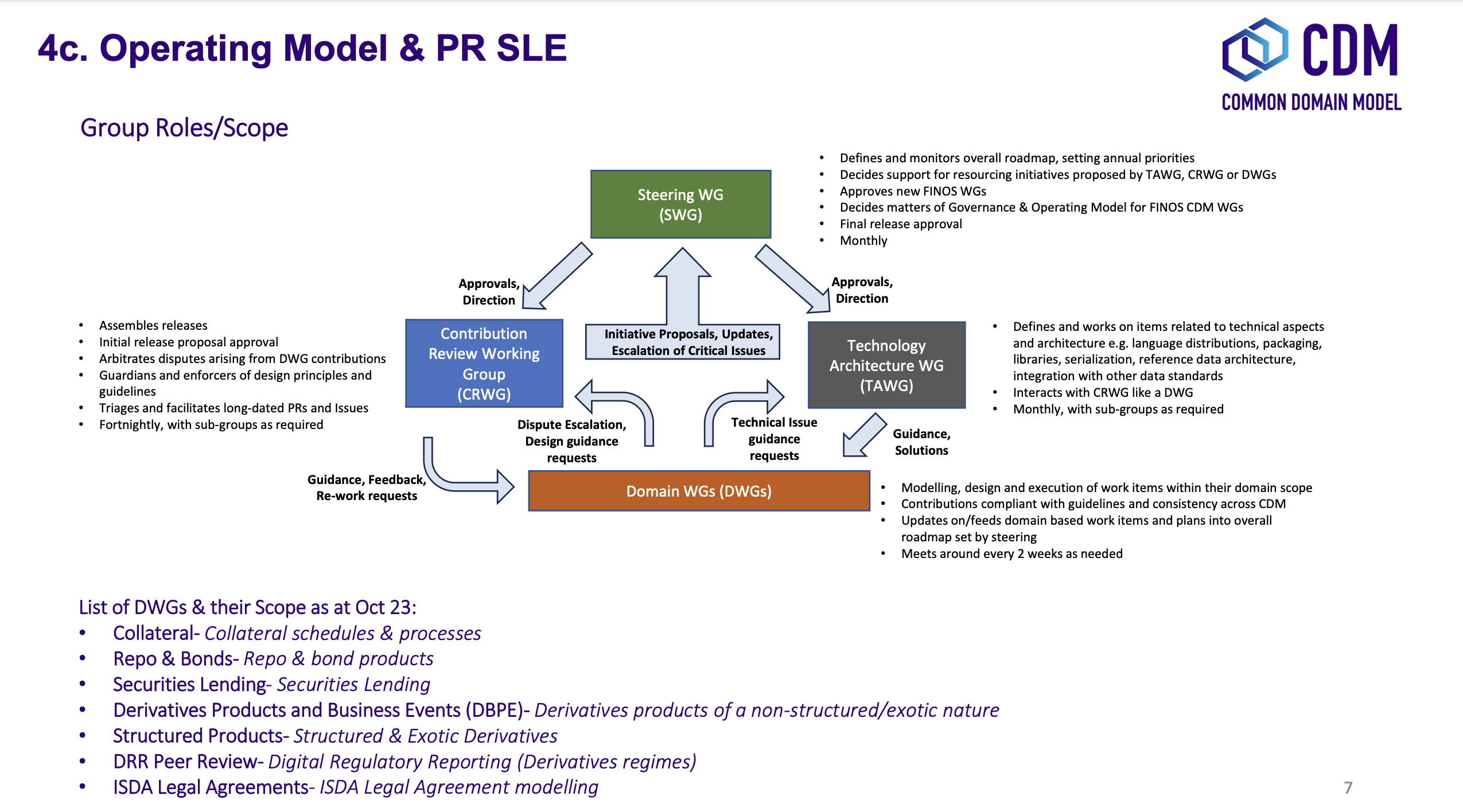
2.2.1 CDM Steering Working Group Purpose: The Steering Working Group is responsible for developing the technical and modelling guidelines, setting and revising the project’s strategic roadmap, and for vetting proposed changes. The CDM Steering Working Group may approve or establish additional working groups.
2.2.2 Appointment of CDM Steering Working Group Maintainers:
- At the launch of the project, up to two initial Maintainers will be nominated by ICMA, ISDA, and ISLA (collectively, the “trade associations”).
- Additional CDM Steering Group Maintainers may be proposed by Participants. Proposed maintainers will be approved via consensus of the Participants and with agreement of existing Maintainers, and should meet the following criteria:
- Proven experience in data modelling and/or software development in financial markets.
- In-depth understanding and proven track record of contribution to the CDM, as well as other data standards (such as ISO) and messaging protocols (such as FIX, FpML or Swift).
2.2.3 CDM Steering Working Group Decision Making: As outlined in governance.md, The CDM Steering Working Group will operate by consensus-based decision-making. Maintainers are responsible for determining and documenting when consensus has been reached. In the event a clear consensus is not reached, Maintainers may call for a simple majority vote of Participants to determine outcomes.
2.2.4 CDM Steering Working Group Appointment of the Editor(s): Editors will review and implement pull requests not expressed in code, test and release new functionalities, resolve bugs and implement approved improvements.
CDM Design Principles
Contributions to the CDM have to comply with the following set of design principles that include the following concepts:
- Normalisation through abstraction of common components
- Composability where objects are composed and qualified from the bottom up
- Mapping to existing industry messaging formats
- Embedded logic to represent industry processes
- Modularisation into logical layers \
CDM development guidelines
The CDM Development Guidelines are defined by the Steering Working Group. The full set of CDM development guidelines can be found here.
Version Management
The CDM is developed, built and released using standard software source-control management. Each new released version is announced to users via a release note that describes the change introduced by that new version. The CDM release history is available in the Release Section of the CDM documentation.
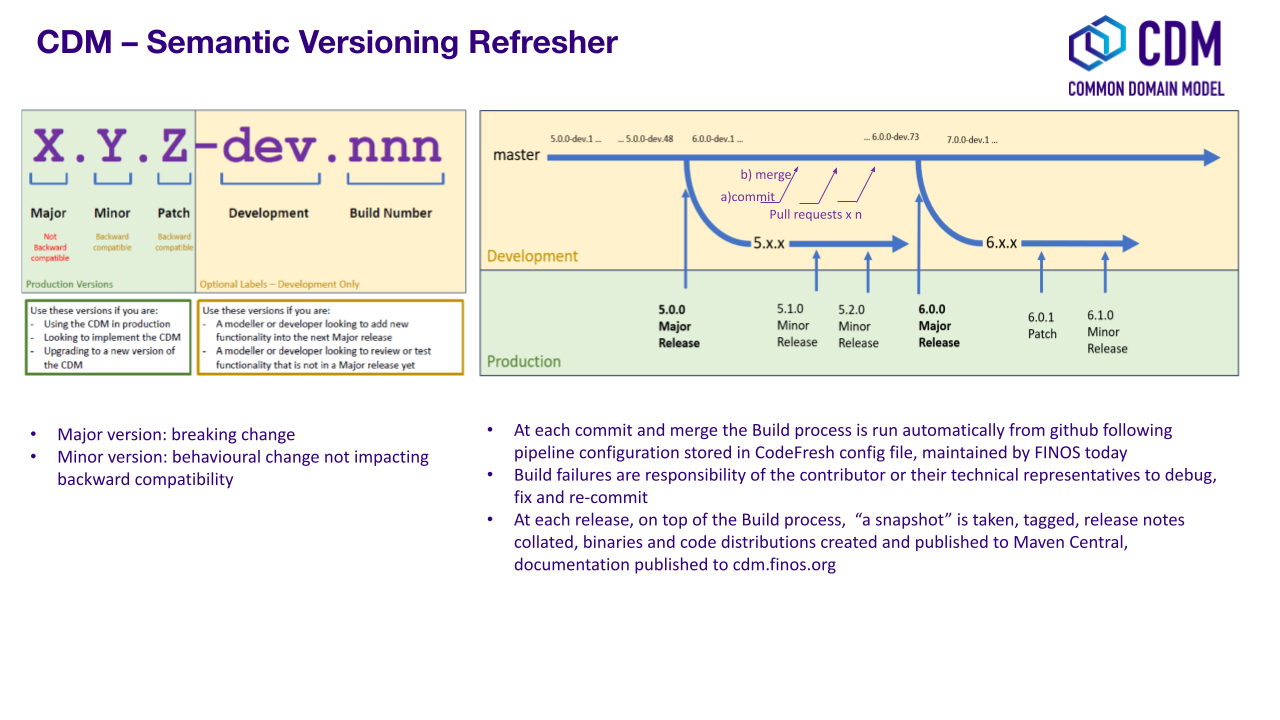
Semantic Versioning
The CDM is released using the semantic versioning 2.0 system - See
SemVer 2.0.0. At high-level, the
format of a version number is MAJOR.MINOR.PATCH (e.g. 1.23.456),
where:
- A MAJOR (
1) version may introduce backward-incompatible changes and will be used as high level release name (e.g. "CDM Version 1"). - A MINOR (
23) version may introduce new features but in a backward-compatible way, for example supporting a new type of event or function. - A PATCH (
456) version is for backward-compatible bug fixes, for example fixing the logic of a condition.
In addition, pre-release versions of a major release will be denoted with a DEV tag as follows:
- MAJOR.0.0-DEV.x (e.g.
1.0.0-DEV.789), where x gets incremented with each new pre-release version until it becomes the MAJOR.0.0 release.
The minor, patch and pre-release numbers may sometimes increment by more than one unit. This is because release candidates may be created but not immediately released. Subsequently, a version associated with the next incremental unit may be released that includes the changes from the earlier release candidate.
Unless under exceptional circumstances, the major number will be incremented by one unit only.
Backward Compatibility
Like other types of software, backward compatibility in the context of a domain model means that an implementor of that model would not have to make any change to update to such version.
- Prohibited changes:
- Change to the structure (e.g. the attributes of a data type or the inputs of a function) or removal of any model element
- Change to the name of any model element (e.g. types, attributes, enums, functions or reporting rules)
- Change to any condition or cardinality constraint that makes validation more restrictive
- Change to the DSL that results in any existing expression becoming invalid
- Change to the DSL that results in change to any of the generated code's public interfaces
- Allowed changes:
- Change that relaxes any condition or cardinality constraint
- Change to any synonym that improves, or at least does not degrade, the mapping coverage
- Addition of new examples or test packs
- Change to the user documentation or model descriptions
- Addition of new data types, optional attributes, enumerations, rules or functions that do not impact current functionality
Exceptions to backward compatibility may be granted for emergency bug fixes following decision from the relevant governance body.
Version Availability
Several versions of the CDM will be made available concurrently, with a dual objective.
- The latest development version (i.e. with a pre-release tag) fosters continued, rapid change development and involves model contributions made by the industry community. Changes that break backward compatibility are allowed. This development version is available in read-only and read-write access on the CDM's modelling-platforms.
- The latest production version (i.e. without any pre-release tag) offers a stable, well-supported production environment for consumers of the model. Unless under exceptional circumstances, no new disruptive feature shall be introduced, mostly bug fixes only. Any change shall adhere to a strict governance process as it must be backward-compatible. Generally, it can only be developed by a CDM Maintainer. This production version is available in read-only access through the CDM's modelling-platforms.
- Earlier production versions, when still supported, are also available in read-only access for industry members who are still implementing older versions of the model. Over time, those earlier production versions enter long-term support in which supportability will be degraded, until they eventually become unsupported.
Example. Assume that the latest major release of the model is 5. The various versions available would be as follows:
- 5.0.0 and any subsequent 5.x would be the latest production version. Backward-compatibility to the initial 5.0.0 version would be maintained for any 5.x successor version.
- The latest 4.x and 3.x may also be supported, but 2.x could be under long-term support and 1.x unsupported altogether.
- 6.0.0-DEV.x would be the latest development version. It can, and will generally, contain changes that are not backward-compatible with version 5. Backward-compatibility between successive 6.0.0-DEV.x versions is also not assured. Once fully developed, version 6.0.0 can be tagged as a major release and becomes the new latest production version.
Note: The above example is for illustration only and not indicative of actually supported CDM versions.
Design Principles
The purpose of this section is to detail the CDM design principles that any contribution to the CDM development must adhere to. The CDM supports the market objectives of standardisation via a set of design principles that include the following concepts:
- Normalisation through abstraction of common components, e.g. price or quantity
- Composability where objects are composed and qualified from the bottom up
- Mapping to existing industry messaging formats, e.g. FpML
- Embedded logic to represent industry processes, e.g. data validation or state-transition logic
- Modularisation into logical layers, using namespace organisation
Normalisation
To achieve standardisation across products and asset classes, the CDM identifies logical components that fulfil the same function and normalises them, even when those components may be named and treated differently in the context of their respective markets. By helping to remove inefficiencies that siloed IT environments can create (e.g. different systems dealing with cash, listed, financing and derivative trades make it harder to manage aggregated positions), such design reaffirms the goal of creating an inter-operable ecosystem for the processing of transactions across asset classes.
An example of this approach is the normalisation of the concepts of quantity, price and party in the representation of financial transactions. The CDM identifies that, regardless of the asset class or product type, a financial transaction always involves two counterparties trading (i.e. buying or selling) a certain financial product in a specific quantity and at a specific price. Both quantity and price are themselves a type of measure, i.e. an amount expressed in a specific unit which could be a currency, a number of shares or barrels, etc. An exchange rate between currencies, or an interest rate, also fit that description and are represented as prices.
This approach means that a single logical concept such as quantity represents concepts that may be named and captured differently across markets: e.g. notional or principal amount etc. This in turn allows to normalise processes that depend on this concept: for instance, how to perform an allocation (essentially a split of the quantity of a transaction into several sub-transactions) or an unwind, instead of specialised IT systems handling it differently for each asset class.
It is imperative that any request to add new model components or extend existing ones is analysed against existing components to find patterns that should be factored into common components and avoid specialising the model according to each use case. For instance, in the model for averaging options (often used for commodity products, whereby multiple price observations are averaged through time to be compared to the option's strike price), the components are built and named such that they can be re-used across asset classes.
Composability
To ensure re-usability across different markets, the CDM is designed as a composable model whereby financial objects can be constructed bottom-up based on building-block components. A composable and modular approach allows for a streamlined model to address a broad scope of operational processes consistently across firms' front-to-back flows and across asset classes. The main groups of composable components are:
- Financial products: e.g. the same option component is re-used to describe option payouts across any asset class, rather than having specialised Swaption, Equity Option or FX option etc. components.
- Business events that occur throughout the transaction lifecycle are described by composing more fundamental building blocks called primitive events: e.g. a partial novation is described by combining a quantity change primitive event (describing the partial unwind of the transaction being novated away) and a contract formation primitive event (describing the new contract with the novation party).
- Legal agreements that document the legal obligations that parties enter into when transacting in financial products are constructed using election components associated to functional logic that is re-usable across different types of agreement: e.g. the same logic defining the calculation of margin requirements can be re-used across both initial and variation margin agreements.
In this paradigm, the type of object defined by the CDM, whether a financial product, business event or legal agreement, is not declared upfront: instead, the type is inferred through some business logic applied onto its constituents, which may be context-specific based on a given taxonomy (e.g. a product classification).
The benefit of this approach is that consistency of object classification is achieved through how those objects are populated, rather than depending on each market participant's implementation to use the same naming convention. This approach also avoids the model relying on specific taxonomies, labels or identifiers to function and provides the flexibility to maintain multiple values from different taxonomies and identifier sets as data in the model related to the same transaction. This has a number of useful application, not least for regulatory purposes.
Mapping
To facilitate adoption by market participants, the CDM is made compatible with existing industry messaging formats. This means that the CDM does not need to be implemented "wholesale" as a replacement to existing messaging systems or databases but can coexist alongside existing systems, with a translation layer. In fact, the CDM is designed to provide only a logical model but does not prescribe any physical data format, neither for storage nor transport. This means that translation to those physical data formats is built-in, and the CDM is best thought of as a logical layer supporting inter-operability between them.
Note: Although the CDM features a serialisation mechanism (currently in JSON), this format is only provided for the convenience of representing physical CDM objects and is not designed as a storage mechanism.
The need for such inter-operability is illustrated by a typical trade flow, as it exists in derivatives: a trade may be executed using the pre-trade FIX protocol (with an FpML payload representing the product), confirmed electronically using FpML as the contract representation, and reported to a Trade Repository under the ISO 20022 format. What the CDM provides is a consistent logical layer that allows to articulate the different components of that front-to-back flow.
In practice, mapping to existing formats is supported by synonym mappings, which are a compact description in the CDM of how data attributes in one format map to model components. In turn, those synonym mappings can support an ingestion process that consumes physical data messages and converts them into CDM objects.
The CDM recognises certain formats as de-facto standards that are widely used to exchange information between market participants. Their synonym mappings are included and rigorously tested in each CDM release, allowing firms that already use such standards to bootstrap their CDM implementation. Besides, because most standard messaging formats are typically extended and customised by each market participants (e.g. FpML or FIX), the CDM allows the synonym representation for those standards to be similarly inherited and extended to cover each firm's specific customisation.
Embedded logic
The CDM is designed to lay the foundation for the standardisation, automation and inter-operability of industry processes. Industry processes represent events and actions that occur through the transaction's lifecycle, from negotiating a legal agreement to allocating a block-trade, calculating settlement amounts or exchanging margin requirements.
While FINOS defines the protocols for industry processes in its documentation library, differences in the implementation minutia may cause operational friction between market participants. Even the protocols that have a native digital representation have written specifications which require further manual coding in order to result in a complete executable solution: e.g. the validation rules in FpML, the Recommended Practices/Guidelines in FIX or CRIF for SIMM and FRTB, which are only available in the form of PDF documents.
Traditional implementation of a technical standard distributed in prose comes with the risk of misinterpretation and error. The process is duplicated across each firm adopting the standard, ultimately adding up to high implementation costs across the industry.
By contrast, the CDM provides a fully specified processing model that translates the technical standards supporting industry processes into a machine-readable and machine-executable format. Systematically providing the domain model as executable code vastly reduces implementation effort and virtually eliminates the risk of inconsistency. For instance, the CDM is designed to provide a fully functional event model, where the state-transition logic for all potential transaction lifecycle events is being specified and distributed as executable code. Another CDM feature is that each model component is associated with data validation constraints to ensure that data is being validated at the point of creation, and this validation logic is distributed alongside the model itself.
Modularisation
The set of files that define the CDM data structures and functions are organised into a hierarchy of namespaces. The first level in the namespace hierarchy corresponds to the layer of the CDM that the components belong to, and those CDM layers are organised from inner- to outer-most as follows:
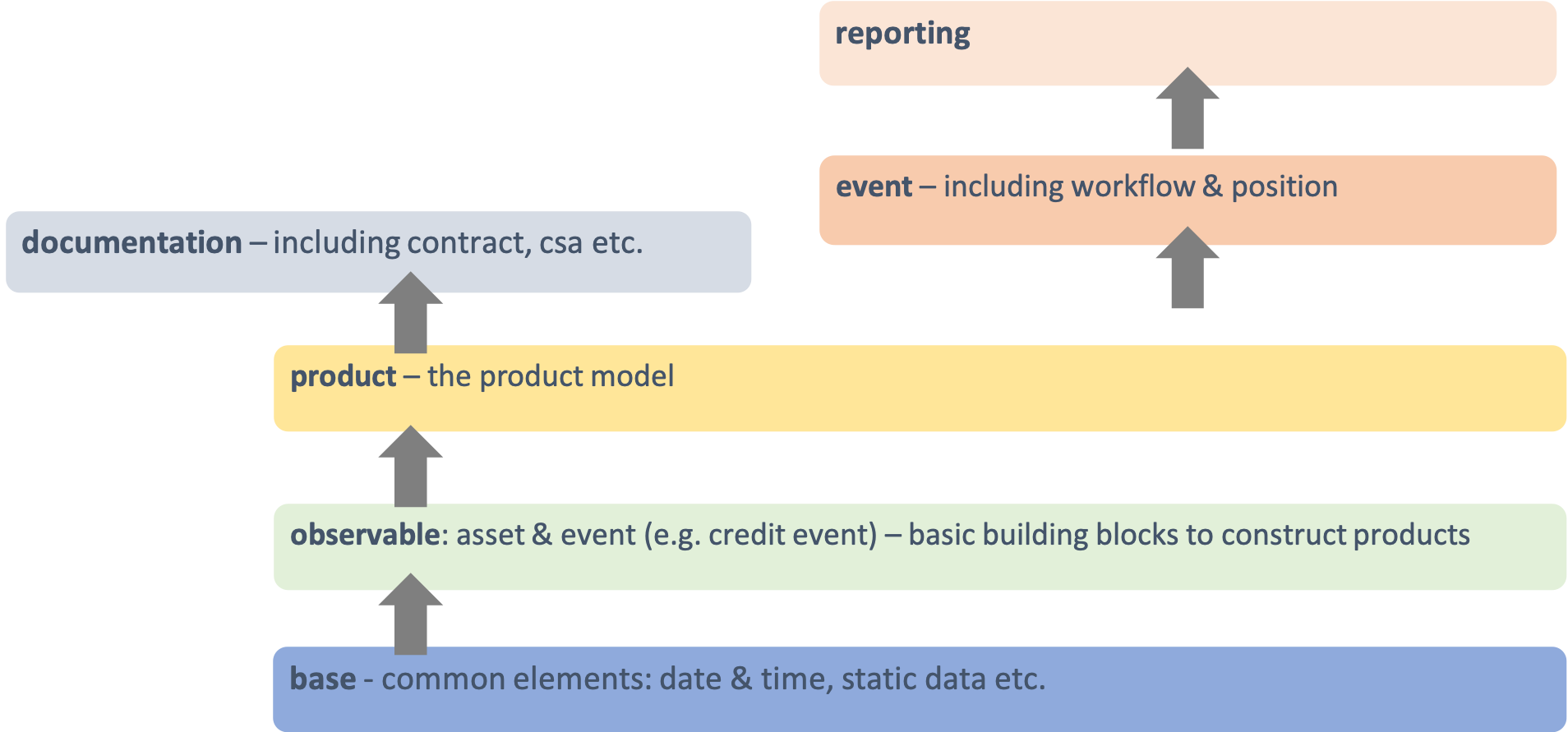
Namespaces have many benefits:
- Accelerated understanding of the model by allowing users to easily see a high-level view of the model and easily find, select, and study specific areas of interest
- Faster and easier to find data types and functions for referencing/use in new components
- Allowing for partial adoption of areas of interest in the model
- Smaller upgrades representing new versions limited to the name spaces that are impacted
Each of these higher-level namespaces is further divided into lower-level namespaces. The independent components in each namespace are organised according to their core purpose but can be referenced from anywhere in the model to allow all the components to work together for a complete modelling solution. E.g. below is the product namespace:

When developing new CDM components, the positioning of those components in the namespace hierarchy is critical as part of the design (or potentially the re-organising of the hierarchy following the new development), to ensure the CDM remains well organised.
Agile Development Approach
The on-going development of the CDM adheres to a methodology inspired by the Agile software development framework. This methodology is based on two high-level principles:
- Focus on business value from the user's perspective, encapsulated in the concept of user story
- Delivery of small, releasable changes that contribute to that business value (sometimes referred to as shippable increments) - i.e. no "big bang" changes
Development by the CDM Maintainer team is being planned along a series of 2-week sprints aligned onto the CDM Architecture and Review Committee cycle. This development is guided by high-level priorities set on a quarterly basis.
Outside contributions that are proposed by industry members, whilst not formally enlisted in the sprint process, usually generate additional tasks (design, review, deployment etc.) for the CDM Maintainer team that will need to be included in a sprint. Those outside contributions still need to comply with the above development principles to ensure a smooth integration with the rest of the development by the CDM Maintainer team.
Focus on business value
Any CDM development work must start from a business case describing the business benefit being sought from the proposed development, as seen from the perspective of the user who will enjoy that benefit. This is know as a user story in the agile framework.
What a user story looks like
A good user story comprises three elements which can be summarised into one sentence: who, what and why.
- Who defines the user (or more generally the set of users defined by some profiling) that will enjoy that benefit
- What defines the feature to be delivered, as a verbal proposition applying to the user - i.e. "the user can do this or that"
- Why specifies the benefit, i.e. what makes this feature important for the user
Since a story is from the user's perspective, it must be written in plain language, or at least in language that is intelligible by that user. It must be free of technical jargon that only the developer of that feature may understand, so that it can be communicated to the user.
Further details about the business case (including documents, pictures, sample data etc.) may be attached to a user story to complement that summary, but the sumamry itself should be whole and self-explanatory.
Story vs task
By contrast, how a story gets delivered is not part of that story:
- How describes the set of tasks that will need to be executed to deliver the story. This is where the story is being decomposed into units of work written in terms that are actionable by the developers.
Tasks will typically map to steps in the software development lifecycle: analysis, design, build, test, deploy. They must be planned before the story is scheduled for development, as part of the sprint planning process. Based on this planning, a set of stories is being prioritised for development in the upcoming sprint. Those stories are communicated to users at the Architecture and Review Committee, but not their underlying tasks or techical details.
Some examples
Instead of writing:
"Commodity Swap Follow Up w/Enum values, mapping, samples"
Which is unclear, assumes some context which not all users may have ("follow-up" from what?) and has no explicit benefit, write:
"A Commodity user of the CDM can map a set of basic Commodity attributes to represent simple Commodity derivative products."
In which some of the underlying tasks may be:
- "Map basic Commodity enumerations"
- "Add Commodity samples to the ingestion test pack"
- etc.
As a rule, a task is written in the imperative mode as an injunction to the developer, whereas a story should be written as a sentence starting with the user's profile as the subject of a verbal proposition. A story written in the imperative mode is more likely a task and improperly written.
For instance, instead of writing:
"Release member contribution for DayCountFraction."
Write:
"A user of interest rate products is able to model products that use the ACT/364 day count convention in the CDM."
Where the "Release" injunction is attached to a deploy-type task.
Delivery of small releasable units
What is a releasable unit
To maintain on-going momentum in the development of the CDM, delivery is organised around small but releasable units of change. This means that any change must be small enough to be achievable during a single sprint (usually), but large enough to be releasable as a cohesive whole. In particular, a change unit should not be regressive or break existing functionality, even if only temporarily (except when retiring such functionality is the purpose of that change) - in agile terms, it must be shippable. This principle applies to on-going development by the CDM Maintainers as well as to outside contributions.
The CDM development approach aligns the concepts of user story and releasable unit, therefore stories should be calibrated to be achievable during a single sprint.
1 contribution = 1 releasable unit = 1 user story
Note: A CDM release may contain more than 1 releasable unit. Every unit should still be shippable in isolation, even if they may end-up being shipped as a group.
Epics
Some larger changes may not be achievable in a single sprint: e.g. if they impact a large number of objects or core features of the model. Such changes are known as epics and need to be decomposed into several user stories. Developers or contributors are responsible for ensuring that the changes are being delivered in small, incremental units and must plan accordingly.
Particularly for complex stories, not all of that story's tasks may necessarily be known in advance and therefore guaranteed to fit in one single sprint. A story may demand some prior analysis before it can be decomposed into development tasks. It may also require several design iterations before development can start. Those prior discovery tasks should be fit into a single sprint and the actual development scheduled in a subsequent sprint.
The discovery phase may reveal that the story is not well calibrated and is in fact an epic that should be further decomposed. This is an acceptable scenario which does not contravene the prescribed development approach, as long as development has not yet started. In that case the story should be requalified and several stories be spun-out as a result, before development can start.
How to Contribute
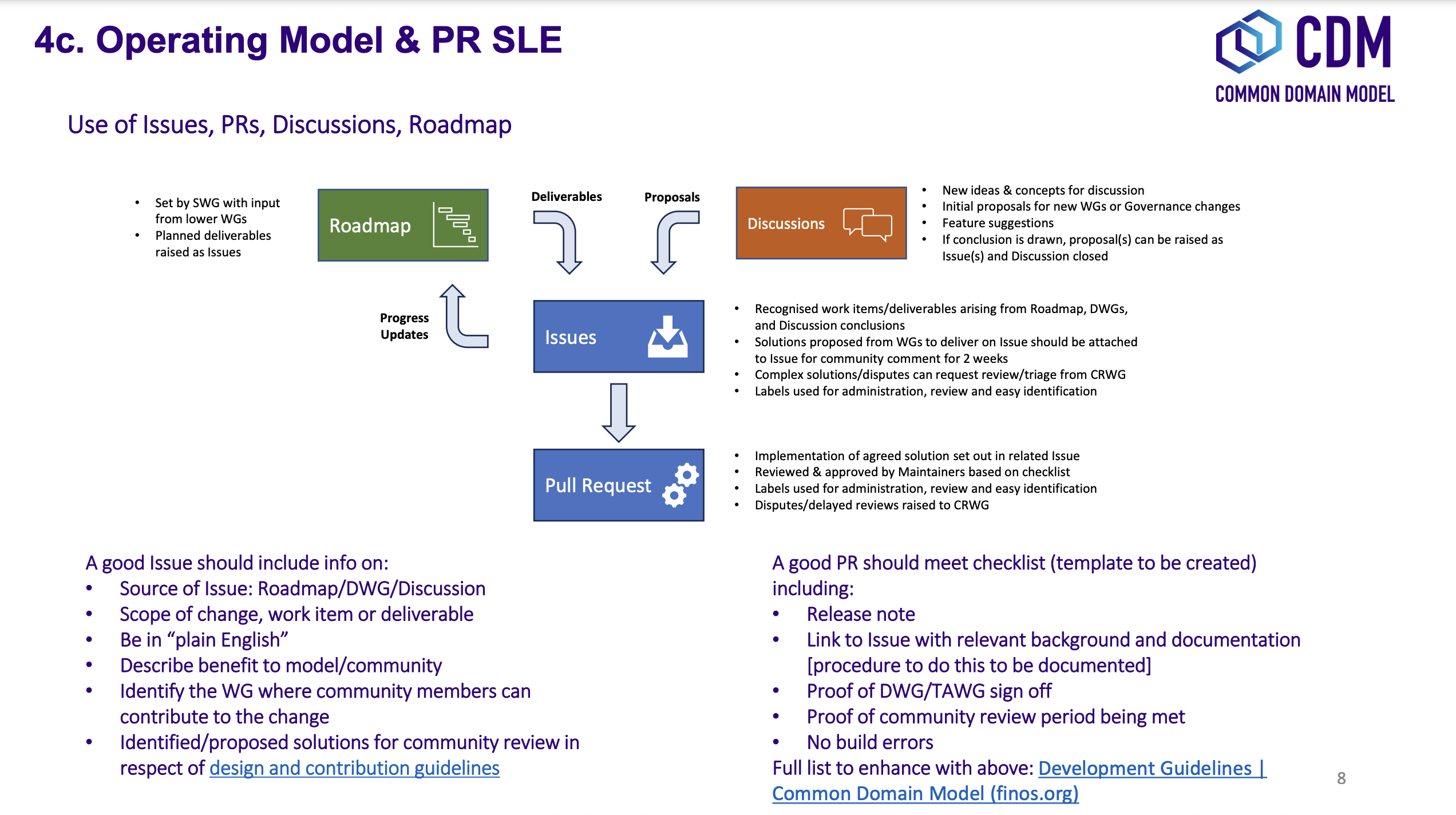
The purpose of this section is to provide guidance for submitting, reviewing and releasing changes to the CDM contributed by the wider industry community including market participants, trade associations and technology or service vendors. It describes:
- What a Contributor should do to edit and contribute changes to the CDM
- What a Maintainer should do to review the changes
- How to release a new CDM version once changes have been approved
::: {#modelling-platforms} Development of the CDM is supported through various modelling platforms, including Rosetta and Legend. Regardless of the modelling platform used, modelling and contribution to the CDM should go through the contribution check-list below.
The steps required to change the CDM are aligned with the software development lifecycle typically applicable to the development of any other software. This development lifecycle is illustrated in the diagram below. Each step is associated to the relevant component of the Rosetta platform that can be used to support the development of the CDM.
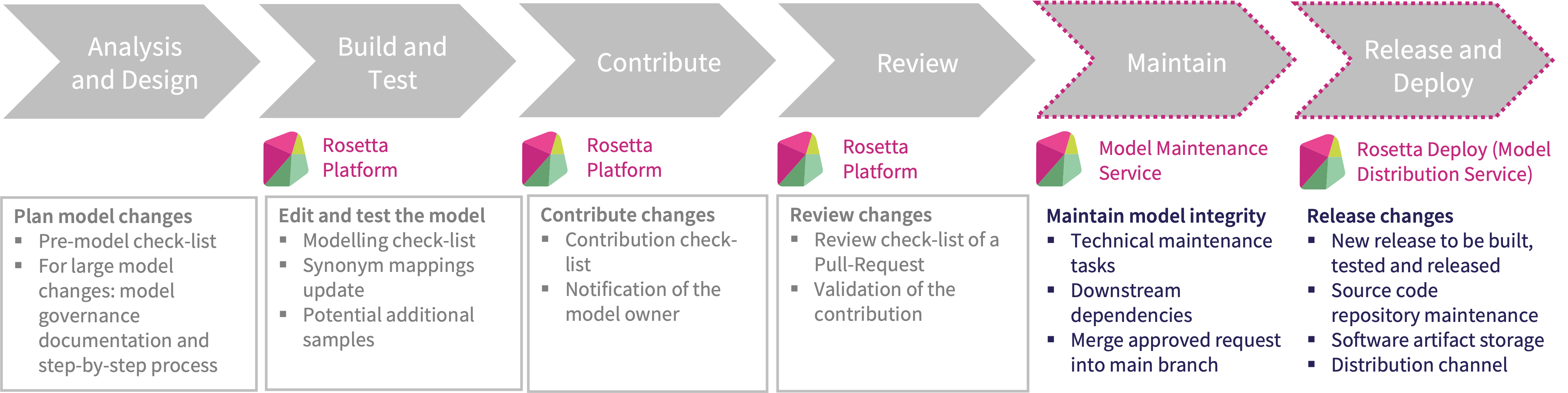
Note: This documentation is not an endorsement of any modelling platform and associated products and CDM users remain invited to leverage the tools of their choosing. This contribution guide has been contextualised with references to Rosetta to ease understanding and align with the current process.
Before you start modelling
Before you start modelling, please make sure you have gone through the following pre-modelling checklist:
- Review the design-principles and governance
- Review the Rosetta Starter Guide or equivalent in your chosen modelling platform.
In addition, for large model changes or changes to core data types, it is recommended that the Contributor reviews the agile-development-approach and follows these steps:
- Define use case. Identify and document one or more use cases with details (e.g. a sample trade).
- Draft conceptual design (high level). Draft a conceptual view showing the set of data types, their definitions (and/or sample attributes but not the whole set of attributes), their relationships to each other, and, if applicable, a workflow.
- Design approval. Obtain approval of high-level conceptual design
from CDM stakeholders:
- CDM Owners (FINOS and other involved Trade Associations, where applicable)
- CDM Sub-Working Group, if applicable
- CDM Architecture and Review Committee
- Quality assurance. Seek the early appointment of at least one CDM Maintainer who can assist modelling discussions and provide early feedback. CDM Maintainers are appointed by the CDM Owners as and when relevant. Please contact cdm@lists.finos.org.
Note: Unless explicitly instructed by a CDM Maintainer, a Contributor can only ever develop changes to a development (i.e. pre-release) version of the CDM.
Editing the model
When editing the CDM, please go through the following modelling checklist:
- CDM version: use the latest available development version
- Syntax: no syntax warnings or errors
- Compilation: model compiles ok with no static compilation errors
- Testing: all translate regression tests expectations for mapping, validation and qualification maintained or improved. Additional test samples may be needed if use-case is not covered by existing samples.
- Namespace: all model components positioned in the correct namespace
- Descriptions: all model components have descriptions
The following sections detail that checklist. When using the Rosetta Design web application to edit the model, the Contributor should also refer to the Rosetta Design Guide.
CDM version
To the extent possible it is recommended that the Contributor keeps working with a version of the CDM that is as close as possible to the latest to minimise the risk of backward compatibility.
Please refer to the Source Control Integration Guide for more information.
Syntax
The model is represented in the Rosetta DSL syntax. All syntax warnings and errors must be resolved to have a valid model before contributing any changes. For further guidance about features of the syntax, please refer to the Rosetta DSL Documentation.
In Rosetta Design, that syntax is automatically checked live as the user edits the model, as described in the Rosetta Design Content Assist Guide.
Compilation
Normally, once the model is syntactically correctly edited, valid code is being auto-generated and compiled. However, certain model changes can cause compilation errors when changes conflict with static code (e.g. certain mapper implementations).
The Rosetta support team can help resolve these errors before the changes are contributed. In most cases you will be able to contact the team via the In-App chat. If the support team identifies that significant work may be required to resolve these errors, they will notify the Contributor who should then contact the CDM Maintainer originally appointed for the proposed change and/or CDM Owners. The latter will be able to assist in the resolution of the issues.
For more information about auto-compilation using the Rosetta DSL, please refer to the Rosetta Auto Compilation Guide.
Testing
The CDM has adopted a test-driven development approach that maps model
components to existing sample data (e.g., FpML documents or other
existing standards). Mappings are specified in the CDM using synonym
which are collected into a Translation Dictionary, and the sample data
are collected into a Test Pack. Each new model version is
regression-tested using those mappings to translate the sample data in
the Test Pack and then comparing against the expected number of mapped
data points, validation and qualification results.
When using Rosetta to edit the model, contributors are invited to test their model changes live against the Test Pack using the Rosetta Translate application, referring to the Rosetta Translate Guide. When editing existing model components, the corresponding synonyms should be updated to maintain or improve existing mapping levels. When adding new model components, new sample data and corresponding synonym mappings should also be provided so the new use-case can be added to the set of regression tests.
Please refer to the Mapping Guide for details about the synonym mapping syntax.
Namespace
All model components should be positioned appropriately in the existing namespace hierarchy. If the proposed contribution includes changes to the namespace hierarchy, those changes should be justified and documented. Any new namespace should have an associated description, and be imported where required.
Please refer to the namespace-documentation section for more details.
Descriptions
All model components (e.g. types, attributes, conditions, functions etc.) should be specified with descriptions in accordance with the CDM Documentation Style Guide.
Contributing model changes
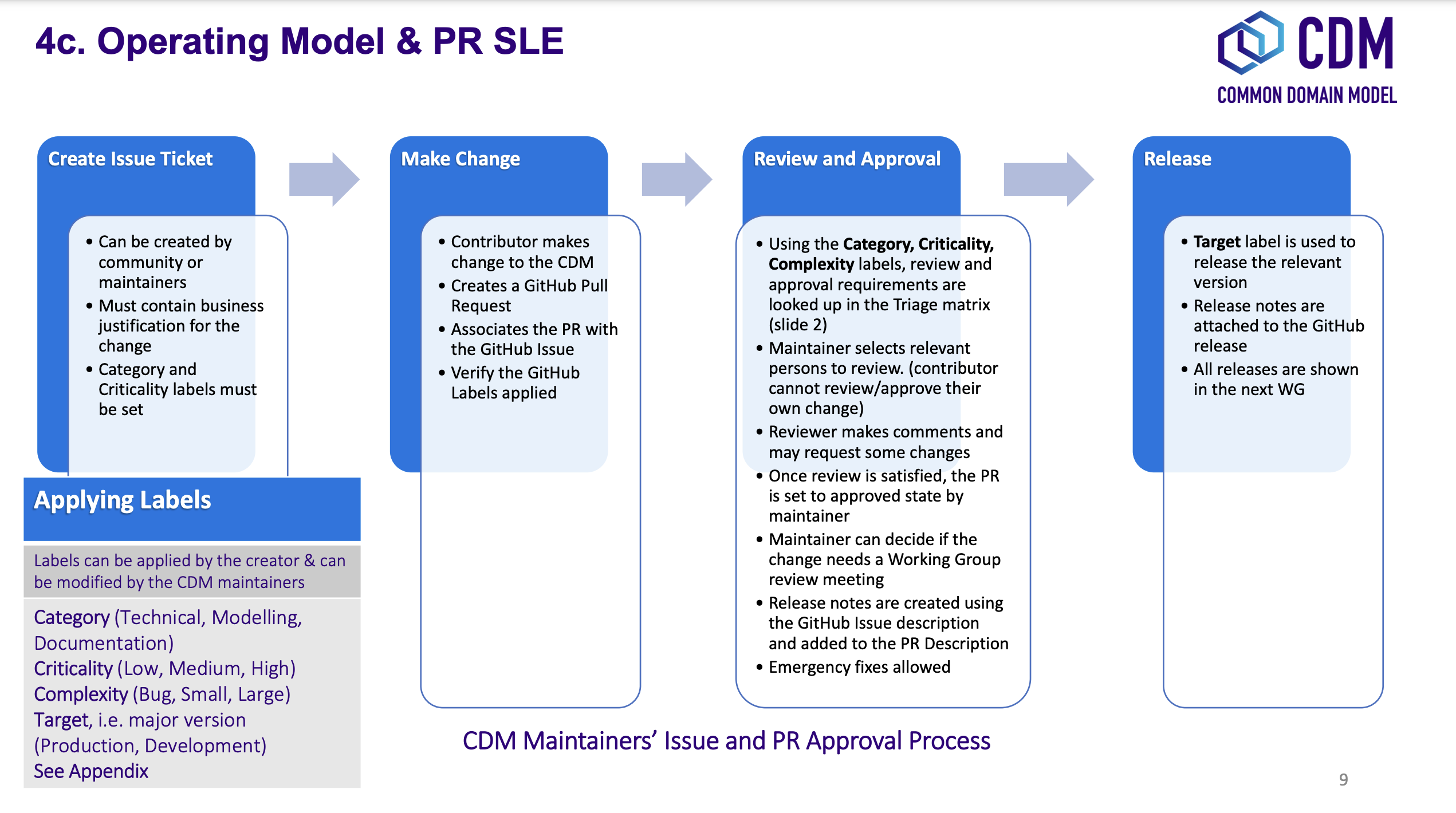
Contribution checklist
Before you start contributing your model changes, please go through the following contribution checklist:
- Specify a meaningful title and description for the contribution
- Notify the CDM Maintainers (via email or Slack) of the submitted contribution
- Include:
- Any notes on expected mapping, validation or qualification changes (success numbers should not decrease)
- Additional data samples, if necessary
- Documentation adjustment, if necessary
- Release notes
- Any other additional materials or documentation that may help with the review and approval process
Note: A contribution should be a whole releasable unit and its size calibrated in accordance with the CDM's agile development approach.
Contributing
Changes are contributed by submitting a Pull Request for review into the CDM source-control repository. This pull request will invoke a build process to compile and run all CDM unit tests and regression tests.
Given the alignment:
1 pull request = 1 contribution = 1 releasable unit = 1 user story,
we recommend labelling the pull request with the user story label, i.e. "STORY-XYZ: ..." to facilitate its tracking.
Note: All contributions are submitted as candidate changes to be incorporated under the CDM licence.
When using Rosetta to contribute model changes, the contribution interface allows to specify a title and description for the contribution. Those inputs are used to create a Pull Request on a one-off branch in the source-control repository. Please refer to the Rosetta Workspace Contribution Guide for more information.
Note: It is not yet possible to contribute updated test expectations, documentation, release notes or new sample data using Rosetta, so these must be provided to the CDM Maintainers via Slack or email.
Documentation
The CDM documentation must be kept up-to-date with the model in production. Where applicable, the Contributor should provide accompanying documentation (in text format) that can be added to the CDM documentation for their proposed changes.
The documentation includes code snippets that directly illustrate explanations about certain model components, and those snippets are validated against the actual model definitions. When a model change impacts those snippets, or if new relevant snippets should be added to support the documentation, those snippets should be provided together with the documentation update.
Release note
A release note should be provided with the proposed model change that concisely describes the high-level conceptual design, model changes and how to review. Please refer to the content-of-release-notes for further guidance on editing release notes.
Reviewing model changes
Review checklist
Before starting to review a contribution, the CDM Maintainer should go through the following review checklist:
- Review Pull Request to assert that:
- Model changes fulfil the proposed design and use-case requirements
- Synonyms have been updated and output (JSON) looks correct
- Contributed model version is not stale and does not conflict with any recent changes
- Changes are in accordance with the CDM governance guidelines
Note: It is not yet possible to verify that mapping, validation and qualification expectations have been maintained by looking at the output of the Pull Request and CDM build only. Please refer to the downstream-dependencies section for more details.
- CDM build process completed with no errors or test failures
- Review additional samples provided (if use-case is not covered by existing samples)
- All model components positioned in the correct namespace
- All model components have descriptions
- Additional documentation provided, if necessary.
- Release note provided
Any review feedback should be sent to the Contributor as required via Slack, email or in direct meetings.
Note: Depending on the size, complexity or impact of a contribution, the CDM Maintainer can recommend for the contribution to be presented with an appropriate level of details with the CDM Architecture and Review Committee for further feedback. The CDM Maintainer will work with the Contributor to orchestrate that additional step. The additional feedback may recommend revisions to the proposed changes. When it is the case the review process will iterate on the revised proposal.
Model maintenance
Before the Pull Request can be merged into the CDM's main branch, some work is usually required by the Maintainer to preserve the integrity of the model source code and of its downstream dependencies.
Post-review technical tasks
A number of technical tasks may need to be performed on the Pull Request once it is approved:
- Stale CDM version: Contribution is based on an old CDM version and model changes conflict with more recent changes. If the conflicting change is available in Rosetta, the contributor should be asked to update their contribution to the latest version and resubmit. If the conflicting change is not yet available in Rosetta, this merge will need to be handled by the CDM Maintainer.
- Failed unit tests: Java unit tests in the CDM project may fail due to problems in the contributed changes. Alternatively it may be that the test expectations need to be updated. The Maintainer should determine the cause of the test failure and notify either the Contributor or work on adjusting the test expectations.
- Additional documentation: If the contributor provided additional documentation, the Maintainer should update the CDM documentation by editing the documentation.rst file in GitHub.
- Documentation code snippets: To avoid stale documentation, the CDM build process verifies that any code snippets in the documentation exists and is in line with the model itself. The Maintainer should adjust or include any code snippets by editing the documentation.rst file on GitHub.
- Code generation: Model changes may cause code generator failures (e.g., Java, C#, Scala, Kotlin etc.). In the unlikely event of code generation failures, these will need to be addressed by the Maintainer.
Downstream dependencies
The CDM has a number of dependent projects that are required for the model to be successfully distributed. It is possible that model changes may cause these downstream projects to fail. The Maintainer will need to test and, if necessary, update those before the changes can be released.
- Translate: The regression tests in this project compare the contributed model against the expected number of mapping, validation and qualification results. Due to the contributed model changes, it is likely that there will be expectation mismatches that cause this build to fail.
- CDM Homepage: compile and test.
- CDM Java Examples: compile and test.
Note: In most cases, the post-review technical tasks and downstream dependencies require software engineering expertise in addition to CDM expertise. Additional technical support from the CDM Maintainer team may need to be called upon to address those.
The change can be merged into the main CDM code base only upon:
- approval by CDM Maintainers and/or CDM Architecture and Review Committee,
- successful completion of all the above technical tasks, and
- successful builds of the CDM and all its downstream dependencies.
Releasing model changes
Once the contributed model change has been merged, a new release can be built, tested and deployed. The Maintainer will work with the CDM Owners and the Contributor on a deployment timeline.
The following release checklist should be verified before deploying a new model:
- Update the CDM version number, using the semantic versioning format
- Build release candidate, and test
- Build documentation website release candidate, and test
- Deploy release candidate and notify channels if need be
- (Currently done at a later stage) Update the latest CDM version available in Rosetta
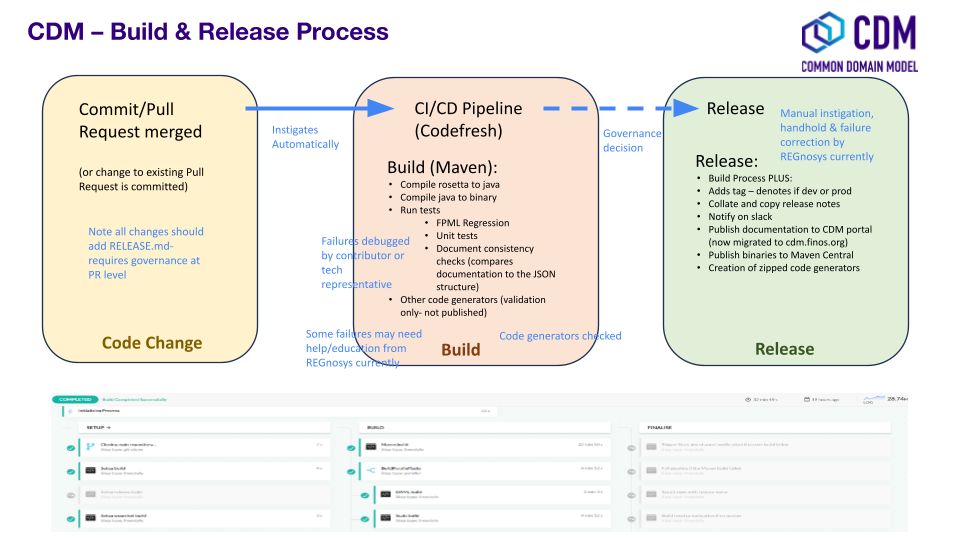
Note: When the release process is handled through Rosetta Deploy, the Maintainer should contact the Rosetta support team to request that deployment and discuss a timeline for the release.
Documentation Style Guide
The purpose of this section is to provide form and substance recommendations for editors of CDM documentation. "Documentation" in this context means any form of written guidance to CDM users and includes:
- the CDM user documentation
- release notes provided with each CDM release
- any description developed in the logical model itself, which
includes:
- data types and attributes
- enumerations
- functions and rules
- test descriptions
- any other areas of the logical model where a textual description may be provided
The intended audience for the CDM documentation includes software developers, data modelers, legal experts, business experts, and other subject matter experts who may have expertise in one area related to financial products, but are not experts in every area.
The baseline for the recommendation is standards for spelling, punctuation, and other style rules applicable to British English. The recommendation in this document extends this rule set with a set of guidelines applicable to documentation for logical models. The recommendation does not provide an exhaustive list of all of the standard British English rules, but provides selective examples that are common to documentation in general.
Writing and editing style is subjective and a matter of personal preferences, rather than right or wrong. The following guidelines are intended to ensure that the documentation provides consistent styling, regardless of who writes it, but should not be interpreted as an authoritative source on "good" styling.
Unless otherwise noted, the recommended rules apply to all forms of CDM documentation. When rules are applicable only to certain forms of documentation (for instance, the logical model descriptions or the release notes), they will be specified as such.
Terminology
The CDM
The model should be referred to as the CDM, without any ownership mention. The only exception is the Overview of the FINOS CDM section at the beginning of the user documentation when the CDM is introduced as the FINOS CDM.
General data definition components
The two data definition components should be referred to as follows:
- Data type: defines an entity with a description, attributes, and
where applicable, conditions.
- Not type.
- Not class: although these are appropriate terms for some of the distributions of the CDM into other languages, they are not applicable for all.
- Attribute: defines a member of a data type.
- Not field.
- Not element.
Product
- Financial Product. The user documentation defines financial-product as the highest level of the hierarchy of the universe of products. The term Financial Product should be used consistently throughout the documentation and wherever applicable in the model descriptions when describing the broad set of products.
- Contractual Product. Similarly,
contractual-product is defined as a
subset of Financial Products and should be used consistently in any
documentation.
- Not Derivatives.
- Not OTC. Contractual Product is at a higher hierarchy level than OTC Derivatives because it can include other types of products such as Security Financing.
Event
- Business Event. In the CDM, a business-event represents an event that may occur during the lifecycle
of a trade, such as an amendment, a termination, a reset or a
payment.
- Not Lifecycle Event. the term Business Event should be consistently used when referring to these data structures in the CDM documentation.
- Primitive Event. In the CDM, a primitive-event represents a building block component used to specify
business events in the CDM.
- Not Primitive (stand-alone). In the CDM documentation, the word Primitive always needs to be qualified with Event, because the word Primitive may be associated to very different meanings, e.g. in computing.
Completeness
User Documentation
- The user documentation should provide an applicable introduction and should have a section for every primary component of the CDM.
- Each section should provide enough business context and explanations of the model so that the average reader in the target audience understands the purpose of the component and its role in the model.
- Each section should have at least one example of a data structure
Logical Model
- Every data type, attribute, enumerated value, function, and test should have a description that describes its purpose in the context of the CDM.
Accuracy
- Descriptions should accurately describe the current state of the model. This seems obvious, but there are many possible ways for introducing misalignments, including: an anticipated change never occurred, or the author incorrectly interpreted the structure, or the data structure changed while the documentation or description was not updated.
- Subtasks in a design process should include an assessment of documentation and descriptions that will be required to be changed or created, and should include the content.
- A release checklist should verify that the affected documentation and descriptions are completed accordingly.
Content Guidelines
General guidelines
- Data Definition components (e.g. data types, attributes,
enumerations and enumerated values) should be explained in business
terms.
- The description of objects in the model should begin with the purpose of the object. The purpose should explain what the object is, not "what it is not".
- Data type description should begin with a verb that describes what the type does.
- The logical model identifies data types without needing a description, therefore, the description should not begin with a phrase like: "A data type that does..."
- Attribute description should articulate the use of the type in the context of the attribute.
- The description should not be tautological, e.g. PartyRole \<defines the party role> is not compliant with these guidelines.
- References to a similar attribute in FpML should not be used as a crutch in place of explaining a data type, attribute, etc.
- In most cases, where a reference to FpML is considered useful, it should be placed at the end of a description in the logical model, or in a note at the end of a section in the user documentation. In the case of the logical model, note that synonyms for FpML are provided, therefore it should not be necessary to reference FpML in every case.
Example of a non-compliant description:
<"A data type to represent a financial product. With respect to contractual products, this class specifies the pre-execution product characteristics (the ContractualProduct class). This class is used as underlying for the option exercise representation, which makes use of the contractualProduct attribute to support the swaption use case, with the exercise into a swap. In a complete workflow, the swaption contract itself then needs to be superseded by a swap contract underpinned by the exercised swap as a contractualProduct.">
Instead a compliant description would state:
<"Represents a financial product. With respect to a contractual products, this data type specifies the pre-execution product characteristics...”>
Another non-compliant example:
<"This class corresponds to the FpML CalculationAgent.model.">
- The description of data objects or the overall model should be
focused on the current state, there should be no reference to the
history of the model or a future state.
- The history of the model is not relevant in this context. It is sufficient to describe how the model currently works.
- Forward-looking statements can create a perception that the product is not finished, and become a distraction to explaining what the product does. Moreover, these future plans may never materialise.
- Given these rules, phrases such as "the model currently does...." should be excluded because any documentation must be a description of what the model currently does.
Heading styles and flow in the user documentation
- Heading styles. The user documentation is edited in the RST
(reStructured Text) mark-up language, which is then rendered into
Html in the CDM documentation website using Sphinx. For headings
to be rendered with the correct structure, they should be annotated
according to the following table:
- If using a header to identify a section to describe a component, then use headers to describe other components that are at the same level.
- Sub-headings should have a name distinct from the higher level heading. e.g. if Legal Agreement is the Heading Level 2, then there should not be a heading at level 3 or 4 with the exact same title.
| Heading Level | Notation (underline in .rst) | Relative font size (as seen by users) | Section Example |
|---|---|---|---|
| 1 | [===============] | XL font and bold | common-domain-model |
| 2 | [---------------] | L font and bold | product-model-page, legal-agreements-page |
| 3 | [\^\^\^\^\^\^\^\^\^\^\^\^\^\^\^] | M font and bold | tradable-product |
| 4 | ["""""""""""""""] | S font (same ascontent), but bold | price-quantity |
:Heading Styles
The RST editing syntax in which the user documentation is written is a standard web mark-up language, for which a reference guide can be found at: https://sublime-and-sphinx-guide.readthedocs.io
- Logical organization and order:
- The user documentation should walk the user through the model from the top down, beginning at a description of the primary components.
- Levels 1 and 2 should include a bullet point list of the sub sections that will be described (bullets formatted with the insertion of an asterisk followed by a space).
- Define business terms and CDM terminology early in a section so that the broader audience understands the model.
- Details about a topic should be presented in the section for that
topic:
- In the case of a model component, the description of the component should always be followed by an example.
- Most or all of the explanation should occur before the example, not after, unless the example was needed as context for an explanation.
- Transitions from one topic to another should be used to help guide the user through the model.
Content of Release Notes
Release notes are text describing the content of any new CDM release and are a critical component of the distribution of that release. Release notes are edited in the Mark-Down (MD) syntax, which is then rendered into Html in the various channels where the release is published.
- Release notes should begin with a high-level headline of the part of
the model being changed, followed by "--" and a short headline
description
- For example: "# Legal Agreement Model - Collateral Agreement Elections"
- They should provide enough detail for a reviewer or other interested parties to be able to find and evaluate the change. For a data model change, for example, the data type and attributes should be named and the before/after states of the model explained, along with a justification in which the issue is summarised.
- They should also embed a link to the Pull Request containing the change, to enable users to inspect those changes in details.
- If the release notes describe mapping rules, there should be explicit information about the examples affected and the change in resulting values for those examples.
- If the release is documentation, it should specify exactly where the document was changed and why.
- Special formatting rules related to use of the MD mark-up language:
- Headline should begin with a
#, as in the above example, so that it appears correctly formatted in Html *before and after text (no space) for bold_before and after text (no space) for italics–(plus a space) for bullets- Backticks `
\before and after model components, e.g. data types, attributes, enums, function names, etc. for special code-style formatting
- Headline should begin with a
Example release notes formatted in MD:
# *CDM Model: Expanded set of enumerations in RegulatoryRegimeEnum*
_What is being released_
Additional regimes have been added to the `RegulatoryRegimeEnum` which is used to express the required regimes for initial margin documentation. The `RegulatoryRegimeEnum` is used as an enumeration for attributes in the `ApplicableRegime` and `SubstitutedRegime` data types within the legal agreements model.
The new enumerated values are `BrazilMarginRules`, `UnitedKingdomMarginRules`, `SouthAfricaMarginRules`, `SouthKoreaMarginRules`, and `HongKongSFCMarginRules`, all of which have come into force in January 2021. Each of these enumerated values has a complete description that uses the text provided in the relevant regulatory supplement.
_Review directions_
In the CDM Portal select the Textual Browser, search for ‘ApplicableRegime’ and ‘SubstitutedRegime’, click on the ‘RegulatoryRegimeEnum’ next to the ‘regime’ attribute and observe the expanded list of regimes, including the ones noted above.
Inspect Pull Request: [#1101](https://github.com/finos/common-domain-model/pull/1101)
The MD editing syntax in which release notes are written is a standard web mark-up language, for which a reference guide can be found at: https://www.markdownguide.org/cheat-sheet/
Note: The MD syntax provides similar features to the RST syntax (used to edit the user documentation), but the special formatting characters are slightly different between the two. While RST allows richer features that are useful for a full documentation website, MD is preferred for release notes because Slack supports (a subset of) the MD language and can therefore serve as a release publication channel.
Style
Content style
- Content should be correct with regard to grammar, punctuation, and
spelling (in British English), including but not limited to the
following rules:
- Grammatical agreement, e.g. data types need, not data types needs
- Punctuation:
- etc. requires a period.
- Complete sentences should end with a period or colon (there should be no need for a question mark or exclamation point in these artefacts).
- Incomplete sentences cannot end with a punctuation. For
example, "Through the
legalAgreementattribute the CDM provides support for implementors to:" is an incomplete sentence and cannot end in a punctuation. This can be fixed by adding a few words, e .g. "Through thelegalAgreementattribute the CDM provides support for implementors to do the following:" - Always use the Oxford Comma (aka the Serial Comma) for clarity when listing more than two items in a sentence, e.g. "data types, attributes, and enumerated values." In extreme cases, failure to use this comma could be costly.
- Other grammatical rules
- Agreement of numbers: For example, if one sentence reads "the following initiatives..." , then it should be followed by more than one.
- Sentences should not end with a preposition
- Non-compliant example: "..to represent the party that the election terms are being defined for."
- Compliant: "...to represent the party or parties for which the election terms are being defined."
- When a name or phrase is defined - continue to use it unless an alias has been defined. For example, one section reviewed had an expression "agreement specification details" but then switched to using "agreement content" without explanation. There is sufficient terminology to absorb, as such there is no need for synonyms or aliases, unless there are commonly used terms, in which case, they should be defined and one term should be used consistently.
- User Documentation and descriptions should always be in the third person, for example: "the CDM model provides the following...". Never use the first person (including the use of "we").
- In the user documentation, when there is a need for a long list, use
bullets (
*or-followed by space, then text) as opposed to long sentences. - To the extent possible, use simple direct sentence structures, e.g. replace "An example of such" with "For example", or replace "Proposals for amendment to the CDM can be created upon the initiative of members of a Committee or by any users of CDM within the community who are not a current Committee member." with "Committee members or any user of CDM within the community can propose amendments to the CDM."
- Exclude the usage of "mean to", "intends to", or "looks to".
- For example, "the model looks to use strong data type attributes such as numbers, boolean or enumerations whenever possible."
- Either the object works as designed or it does not. This expression might be used in a bug report when describing a function not working as intended but not to describe a production data model.
- Explain the CDM objects in an honest and transparent manner, but without criticism of the model. Sentences such as: "...which firms may deem inappropriate and may replace by..." or "the model is incomplete with regards to..." are unnecessary in a documentation. Rather, issues which may be identified in the CDM should be raised and addressed via the CDM governance structure.
Special format for CDM objects
- Data types and attributes display rules:
- Data types and attributes should be identified in the editor
with code quotes, where the text between the quotes will appear
in a special block format as illustrated here:
LegalAgreementBase. - If the same word or phrase is used in a business context, as part of an explanation, then the words should be spaced and titled normally and the special format is not required: e.g. "Tradable products are represented by...".
- Data types and attributes should be identified in the editor
with code quotes, where the text between the quotes will appear
in a special block format as illustrated here:
- Code snippets should be preceded by the string:
.. code-block:: Language(where the Language could be any of Haskell, Java, JSON, etc.), followed by a line spacing before the snippet itself. The entire snippet should be indented with one space, to be identified as part of the code block and formatted appropriately. Indentation can be produced inside the snippet itself using further double space. Meta-data such as data type descriptions or synonyms that appear in the CDM should be excluded from the code snippet, unless the purpose of the snippet is to illustrate those.
Example of how a code snippet should be edited in the documentation:
.. code-block:: Haskell
type Party:
[metadata key]
partyId PartyIdentifier (1..*)
name string (0..1)
[metadata scheme]
businessUnit BusinessUnit (0..*)
person NaturalPerson (0..*)
personRole NaturalPersonRole (0..*)
account Account (0..1)
contactInformation ContactInformation (0..1)
And the result will be rendered as:
type Party:
[metadata key]
partyId PartyIdentifier (1..*)
name string (0..1)
[metadata scheme]
businessUnit BusinessUnit (0..*)
person NaturalPerson (0..*)
personRole NaturalPersonRole (0..*)
account Account (0..1)
contactInformation ContactInformation (0..1)
Note: Code snippets that appear in the user documentation are being compared against actual CDM components during the CDM build process, and any mismatch will trigger an error in the build. This mechanism ensures that the user documentation is kept in sync with the model in production prior to any release.
Fonts, Text Styles, and Spaces
- Bold should be used sparingly:
- Only in the beginning of a section when there is a salient point to emphasize, like a tag line - the bold line should be syntactically complete and correct.
- In the editor, bold is specified with double asterisks before and after the word or phrase.
- Italics
- Italics should be used when defining an unusual term for the first time rather than using quotes, for example to identify something CDM specific, such as the concept of Primitive Events.
- In the editor, italics is specified with a single asterisk
*before and after the word or phrase.
- Single space should be used in-between sentences, not double space.
Style references for additional guidance
- New Hart's Rules: An updated version of this erstwhile comprehensive style guide for writers and editors using British English, published by the Oxford University Press. Invaluable as an official reference on proofreading and copy-editing. Subjects include spelling, hyphenation, punctuation, capitalisation, languages, law, science, lists, and tables. An earlier version coined the phrase Oxford Comma in July 1905.
- Eats, Shoots & Leaves: The Zero Tolerance Approach to Punctuation: A light-hearted book with a serious purpose regarding common problems and correctness for using punctuation in the English language.